Over a 10-part blog series, I have explored how AI is reshaping the world of data engineering. I started by demystifying AI-augmented data engineering; what it really means and why it matters. From there, I walked through tools, architectures, and real-world use cases. In my previous blog, I grounded the discussion with practical case studies, showing how organizations are already seeing impact. If you missed it, you can check it out here.
Now, I arrive at the question everyone is asking:
Will AI Replace Data Engineers?
Simple answer: No, AI will not replace data engineers.
However, what it will replace are many of the tasks data engineers perform today. This shift is not about eliminating roles, but about reshaping them to focus on higher-value work.
As AI takes over repetitive ETL coding, the role of the engineer will naturally evolve. Engineers will move away from manual implementation and toward coordination and oversight. They will orchestrate AI agents, guide copilots in the right direction, and validate auto-generated pipelines to ensure quality and accuracy. At the same time, they will spend more energy innovating at the intersection of data, business, and AI.
The work changes, but the importance of the data engineer does not. It simply moves to a more strategic and impactful level.
What Will Still Require Human Judgment?
| Area | Why AI won’t fully replace it yet |
The Rise of Prompt Engineers in Data
As LLMs are increasingly integrated into data platforms, a new capability is emerging: Prompt engineering.
The role focuses on designing prompts that produce pipelines, schemas, and validations, refining outputs through context-rich inputs, and translating engineering intent into instructions that GenAI copilots can execute.
In practice, this marks a shift in how work gets done. Prompting becomes the new scripting. It is less about writing every line of code and more about guiding intelligent systems to produce the right result.
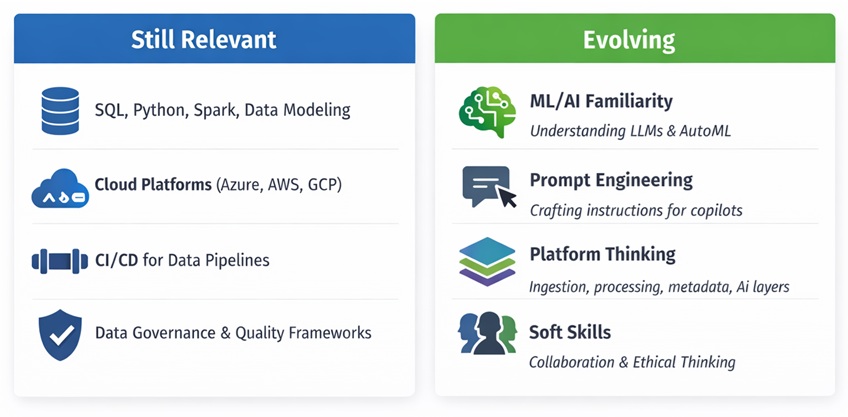
Skills That Data Engineers Will Need in 2026 and Beyond
Closing Thoughts
In the age of AI, the data engineer of the future is not replaced but augmented. Just as DevOps engineers evolved alongside automation tools, data engineers will evolve alongside AI copilots. AI will write code, suggest schemas, and monitor pipelines, while humans will remain responsible for orchestrating the bigger picture. Those who succeed in this transition will be the ones who embrace augmentation rather than fear it. The real shift is not about choosing between AI and humans, but about how effectively humans learn to work with AI.
Final Reflection: Series Summary
The journey across this blog series has covered:
- Introduction to AI-augmented data engineering
- How AI is changing the data engineering lifecycle
- LLMs in data engineering: Opportunities and challenges
- Smart data pipelines with AI: Architecture & patterns
- AI for data quality and validation
- AI-powered documentation and metadata management
- Comparison of AI capabilities in Databricks, Snowflake, and Microsoft Fabric
- How to build an AI-augmented data platform
- Real-world use cases of AI-augmented data engineering
This is just the beginning. As the tools mature, AI will become an embedded ally in every data engineering workflow. Now’s the time to adapt, upskill, and lead this change.

Author
Pragadeesh J
Director – Data Engineering | Neurealm
Pragadeesh J is a seasoned Data Engineering leader with over two decades of experience, and currently serves as the Director of Data Engineering at Neurealm. He brings deep expertise in modern data platforms such as Databricks and Microsoft Fabric. With a strong track record across CPaaS, AdTech, and Publishing domains, he has successfully led large-scale digital transformation and data modernization initiatives. His focus lies in building scalable, governed, and AI-ready data ecosystems in the cloud. As a Microsoft-certified Fabric Data Engineer and Databricks-certified Data Engineering Professional, he is passionate about transforming data complexity into actionable insights and business value.