In my last blog, “Comparing AI Capabilities in Databricks, Snowflake, and Microsoft Fabric,” I explored how each platform brings its own differentiators, strengths, and best-fit use cases. That discussion set the foundation for understanding how modern data platforms are evolving with embedded AI capabilities. If you missed it, you can check it out here.
In this blog, I will take the next step in that journey, moving from platform capabilities to platform design. As data complexity grows and decision-making windows continue to shrink, enterprises are increasingly turning to AI-augmented data platforms to accelerate insights, automate pipelines, and enhance data-driven outcomes.
That naturally brings us to the next question: “How can we design an end-to-end data platform that’s truly AI-augmented: intelligent by design, not by add-on?”
What is an AI-Augmented Data Platform?
In simple terms, an AI-augmented data platform combines the reliability and scalability of a modern data lakehouse with the adaptability and automation of AI. It is not just a storage or processing system. It is a self-optimizing ecosystem that learns from data usage patterns, automates manual tasks, and accelerates time-to-insight. Think of it as the evolution from “data at scale” to “intelligence at scale.”
Core Pillars of the Architecture
An AI-augmented data platform can be visualized as a series of horizontal layers (from ingestion to consumption) with vertical enablers (governance, observability, security) cutting across them. Let’s explore each layer in detail.
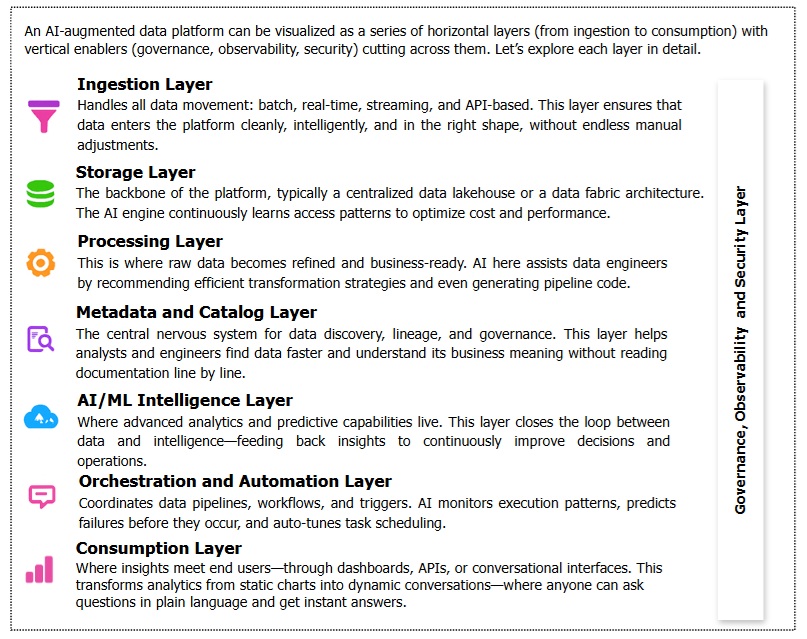
Cross-Cutting Concerns
Across all layers, certain enterprise features remain foundational:
- Security & Compliance: PII masking, role-based access control, and automated policy enforcement
- Data Governance: Auto-classification, compliance scoring, and auditability
- Monitoring & Observability: ML-powered alerting, data drift detection, and health dashboards
- Cost Optimization: Usage analytics and AI-based cost recommendations
These pillars ensure that intelligence doesn’t come at the cost of control or compliance.
Technology Stack Options
| Layer | Tools | AI Augmented Additions |
Implementation Tips
- Start small: Begin with one AI-driven use case like automated data quality checks or smart cataloging.
- Adopt open architectures: Design with cloud-neutral, pluggable components.
- Keep humans in the loop: Ensure oversight on AI-driven actions and decisions.
- Iterate and learn: Build maturity layer by layer, don’t try to automate everything at once.
Conclusion
AI-augmented data platforms are not just about embedding AI features. They represent a fundamental shift in how data is ingested, governed, processed, and consumed with intelligence and automation at the core. In the next blog, I will explore real-world use cases that show how AI-Augmented Data Engineering is already transforming modern data ecosystems.
Continue the journey here as I explore real-world use cases of AI-augmented data engineering

Author
Pragadeesh J
Director – Data Engineering | Neurealm
Pragadeesh J is a seasoned Data Engineering leader with over two decades of experience, and currently serves as the Director of Data Engineering at Neurealm. He brings deep expertise in modern data platforms such as Databricks and Microsoft Fabric. With a strong track record across CPaaS, AdTech, and Publishing domains, he has successfully led large-scale digital transformation and data modernization initiatives. His focus lies in building scalable, governed, and AI-ready data ecosystems in the cloud. As a Microsoft-certified Fabric Data Engineer and Databricks-certified Data Engineering Professional, he is passionate about transforming data complexity into actionable insights and business value.