AI‑augmented data engineering has moved beyond experimentation. Across industries, it is now delivering measurable gains in the speed, quality, and reliability of data pipelines. In the previous blog, I explored the architectural foundations of AI‑augmented platforms, and a full‑stack reference architecture spanning ingestion to consumption. If you missed it, you can check it out here.
In this blog, I focus on real‑world use cases where AI is embedded directly into data engineering workflows, driving outcomes, not just insights. These are not hypothetical scenarios; they reflect how leading organizations are operationalizing AI across the data lifecycle.
Use Cases – Healthcare, Finance & Retail
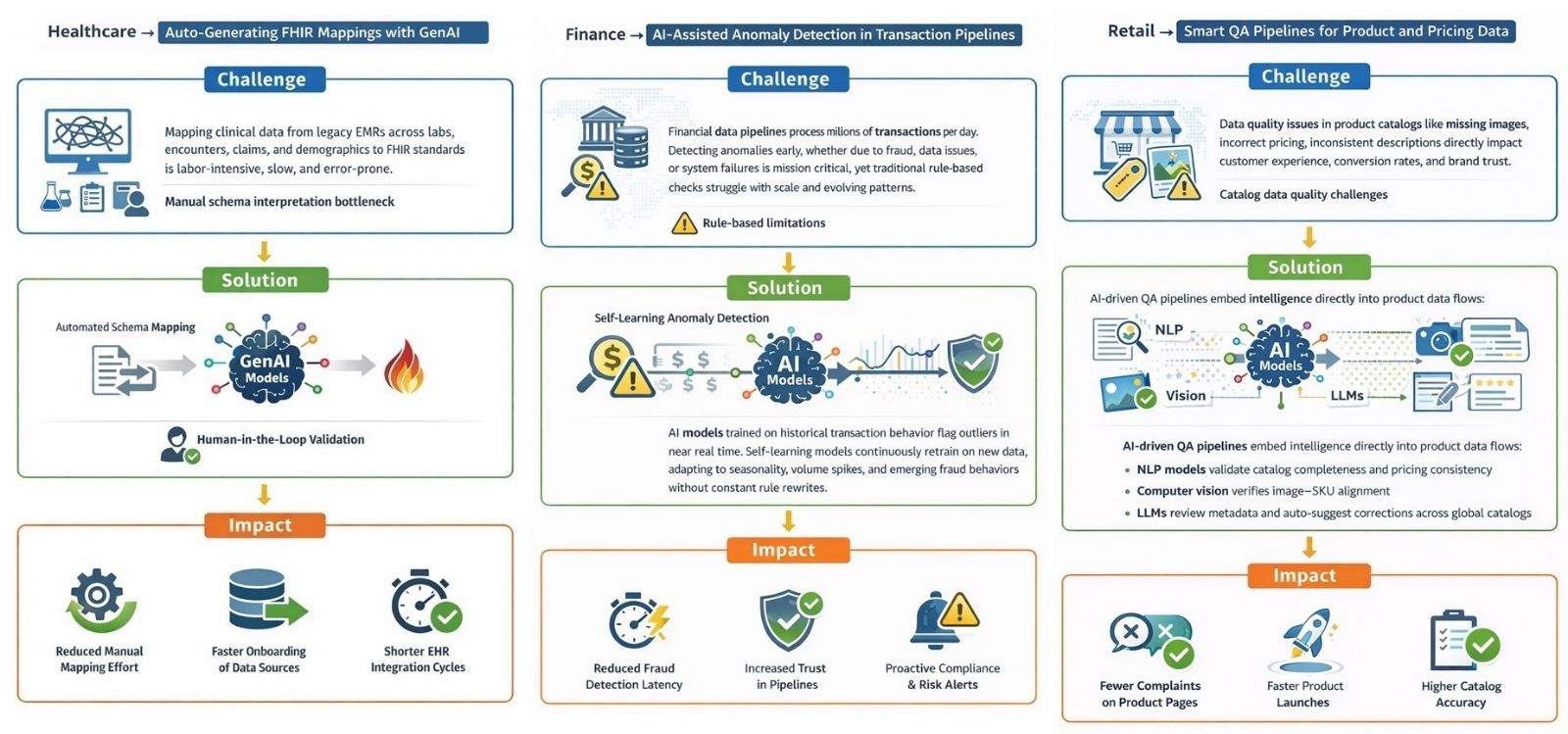
Other Use Cases Across Industries
| Industry | Use Case | AI Augmentation | Impact |
Key Takeaways
- AI‑augmented data engineering is operational and measurable in production environments, not a buzzword.
- Treat AI as a first‑class component of data pipelines, not an afterthought at the analytics layer.
- Focus on augmentation rather than automation‑only approaches.
- Design for human‑in‑the‑loop feedback so pipelines continuously improve over time.
Closing Thoughts
AI‑augmented data engineering is no longer a futuristic concept. It is actively reshaping how modern data platforms operate. From automating schema mappings to detecting anomalies and intelligently validating data, organizations are leveraging AI to:
- Accelerate data workflows
- Enhance reliability, governance, and trust
- Empower data teams with intelligent, actionable insights
AI doesn’t replace data engineers; it amplifies them. By offloading repetitive, error‑prone tasks to intelligent systems, data teams can focus on higher‑order design decisions, innovation, and business impact.
In the final blog of this series, I will explore what the future of data engineering will look like, as AI and GenAI become native capabilities of data platforms, and how teams can prepare for what comes next.

Author
Pragadeesh J
Director – Data Engineering | Neurealm
Pragadeesh J is a seasoned Data Engineering leader with over two decades of experience, and currently serves as the Director of Data Engineering at Neurealm. He brings deep expertise in modern data platforms such as Databricks and Microsoft Fabric. With a strong track record across CPaaS, AdTech, and Publishing domains, he has successfully led large-scale digital transformation and data modernization initiatives. His focus lies in building scalable, governed, and AI-ready data ecosystems in the cloud. As a Microsoft-certified Fabric Data Engineer and Databricks-certified Data Engineering Professional, he is passionate about transforming data complexity into actionable insights and business value.