
In the previous blog, I explored how AI enhances data quality and validation, from detecting outliers with ML models to imputing missing values and identifying schema drifts. I even explained how ML helps us move beyond rigid, rule-based checks toward adaptive, intelligent validation strategies. In case you missed it, read it here
In this blog, the focus shifts to one of the most persistent challenges in data engineering: documentation. Maintaining accurate, up-to-date metadata, lineage, and descriptions has long been a tedious, error-prone task. With AI, documentation can evolve into a living, automated asset, reducing manual overhead, improving transparency, and embedding intelligence directly into the data lifecycle.
Why is today’s documentation a bottleneck?
Data ecosystems grow fast. Pipelines evolve. Schemas change. Teams rotate. Amidst this pace, metadata and documentation often lag behind or become outdated altogether. Manual documentation is time consuming, prone to human error, and often deprioritized during delivery sprints. Robust documentation is, therefore, essential for:
- Data discoverability
- Better governance and compliance
- Impact analysis and debugging
- Seamless onboarding of resources and cross-team collaboration
AI-driven solutions for managing metadata
-
Lineage graph generation from code
AI models can parse and understand code in SQL, Spark, Python, and orchestration logic (like Airflow, ADF) to generate precise data lineage maps. These models, including LLMs and code parsers, extract the semantic meaning and logical flow of data, eliminating the need for manual mapping.
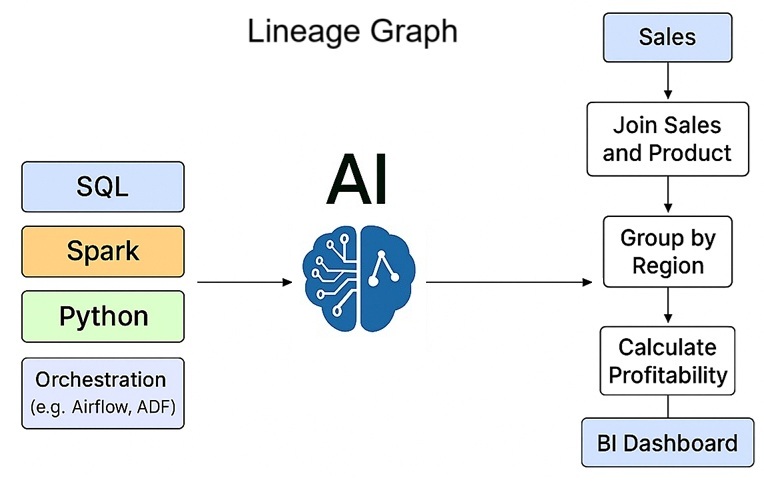
This ensures lineage is always in sync with the evolving codebase, accurately showing the source-to-target flow, transformations applied, and dependencies between jobs and tables. The automated approach provides a dynamic and reliable view of your data landscape.
-
Entity and relationship detection
AI can infer logical entities (e.g., customer, product, order) and relationships between tables using metadata, field names, sample data and code context. Techniques like clustering based on naming patterns, LLM-driven context analysis, and statistical co-occurrence patterns can be used to detect the same. This allows intelligent grouping of assets in catalogs and supports knowledge graph generation.
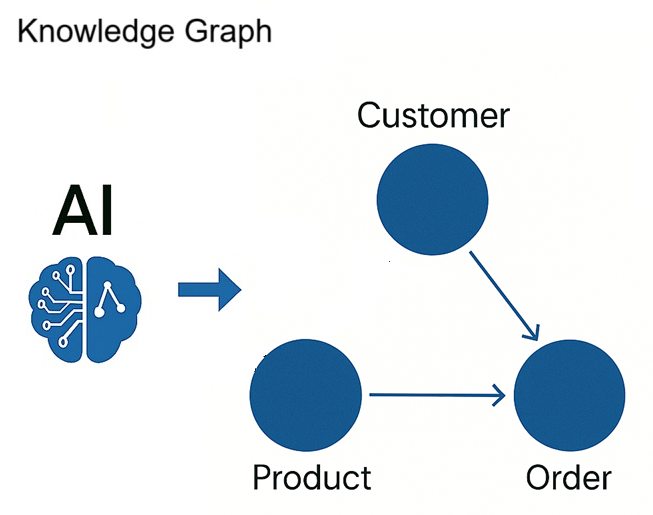
-
NLP-based column description generation
AI models can now automate the creation of data documentation. They analyze a column’s field name, data type, and usage context to generate clear, readable descriptions. LLMs trained on data dictionaries and contextual clues like the table name or pipeline logic can infer the column’s purpose and provide concise summaries.
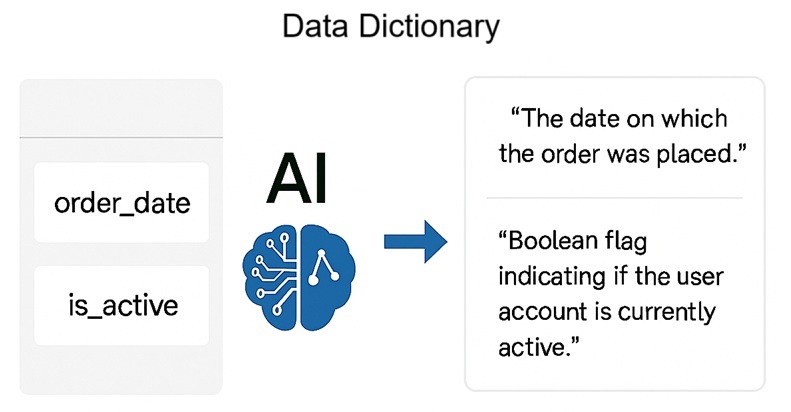
This automation offers several key benefits:
- Accelerates documentation
- Supports data cataloging tools (e.g., Unity Catalog, Alation, Acryl Data)
- Improves user understanding and self-service analytics
Integration of AI-driven documentation into the data platform
An AI-driven documentation engine typically integrates with catalogs, wikis, and governance platforms. Below is a depiction of how it works:
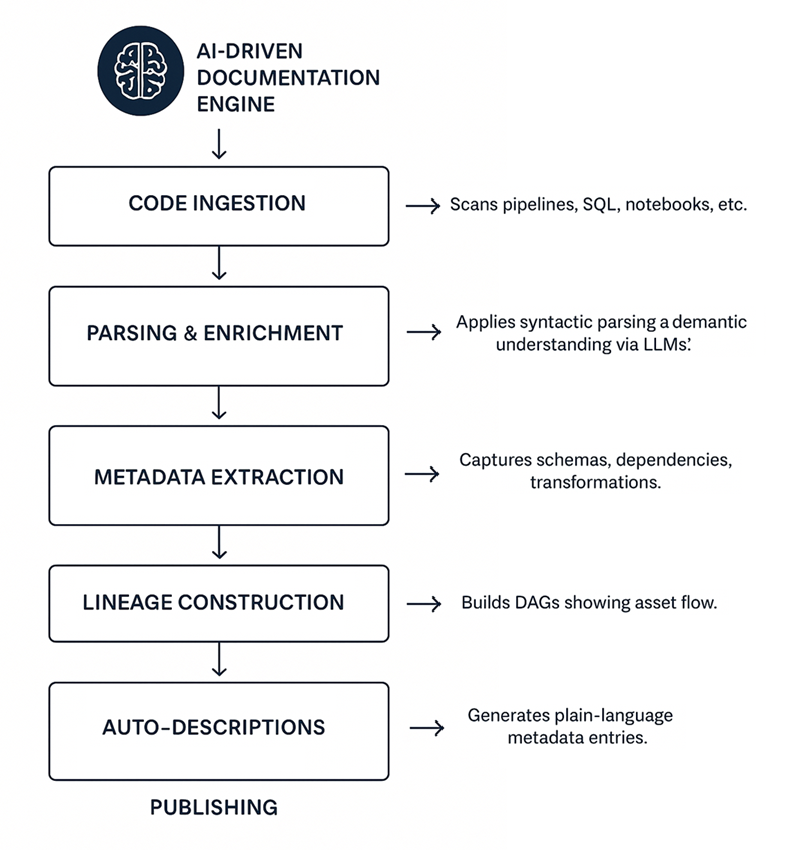
Implementation considerations
- Accuracy vs. explainability: LLM outputs must be reviewed initially for correctness.
- Version control: Documentation should evolve with pipeline/code changes.
- Human-in-the-loop: Offer editing, approval, and override mechanisms.
- Security & PII handling: Sensitive fields need tagging and masking where applicable.
Closing thoughts
AI is reshaping metadata management from a chore to a strategic enabler. By automating lineage, descriptions, and structure inference, data teams can maintain clarity and control even as their environments scale in complexity. What once required weeks of manual work can now be continuously generated and updated.
Well-documented pipelines are no longer just a “nice to have”. They are foundational to trust, compliance, and operational agility. AI makes that foundation more scalable and sustainable than ever before.
Continue the journey here as I compare AI Capabilities in Databricks, Snowflake, and Microsoft Fabric.

Author
Pragadeesh J
Director – Data Engineering | Neurealm
Pragadeesh J is a seasoned Data Engineering leader with over two decades of experience, and currently serves as the Director of Data Engineering at Neurealm. He brings deep expertise in modern data platforms such as Databricks and Microsoft Fabric. With a strong track record across CPaaS, AdTech, and Publishing domains, he has successfully led large-scale digital transformation and data modernization initiatives. His focus lies in building scalable, governed, and AI-ready data ecosystems in the cloud. As a Microsoft-certified Fabric Data Engineer and Databricks-certified Data Engineering Professional, he is passionate about transforming data complexity into actionable insights and business value.


